Industry news
Topological Data Analysis(TDA) 拓扑数据分析与mapper算法

?训练的原始数据为7类3D模型数据,为了使这些模型能够成为mapper算法的输入,需要进行一些预处理,即在这些模型中抽取4000个具有代表性特征的点构成集合Y(这是对一个模型抽取4000个点),重新表示该3D模型。
? ? ? ? 得到点集Y后,这时我们就选择一个合理的filter函数,比如
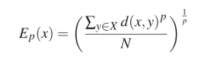

?这个函数的作用就是,对于每个模型中采集的点,能够计算该点距离所有点的中心的远近程度,离中心越远的点值越大。不明白的话,直接看下图:

?上面这个图就是通过那个filter函数计算后的值的分布。就拿那个大象来说,腹部那里应该算的上是点的中心部分,所以值最小程蓝色。鼻子和后腿离中心较远,所以值最大程红色。那么经过filter函数计算后有什么用呢?
? ? ? ? 到了这里,我们再回过去看mapper算法的流程那里,此时我们已经得到该3D模型中每个点对应的一个值。这些值就是一维的数据。这样就可以设置resolution和overlap了。
下图中的U代表intervals的宽度,U重叠的部分就是overlap。


?从上面的拓扑图可以看到,对于不同类别的物体,其拓扑图完全不一样。对于相同类别的物体他们动作不一样,拓扑图也能够体现出来,即使变化很微小(如人脸的表情)。
优点2:能够发现一些更小的类。
? ? ? ? 我们来看一个例子:
输入数据为3168个语音记录样本,这些样本来自男性和女性的发言者。每个数据有21个属性。如下图:

?使用mapper算法后进行可视化:


?
其中红色圈表示女性,黄色圈表示男性,蓝色圈表示男性和女性都有。图 3 和图 4 清楚地向我们展现了数据中隐藏的形状,以及从不同尺度观察数据的结果。由图 4?可知,男性和女性样本被有效区分,在同性中存在不同的簇,说明同性之间的声音也有不同的类 别,而在异性间存在共同的簇,说明即使异性之间 的声音也会有相似特征和成分。由图 3?可以明显看到簇的减少(更加粗糙),以及更加明显的聚类和数据形状,虽然整个数据的形状有点扭曲变形,但是 Y 形耀斑这样的基本特征仍然存在,说明 TDA 的确对小误差的容忍度很大,数据簇更加明确。
?优点3:发现的特征具有鲁棒性
先看一下专家原话:

?意思就是,如果一个特征,能够在不同粗糙程度的角度持续被检测到,那么这个特征多半不可能是 artifact的 而是 real的。从图3和图4中(代表不同的粗糙程度)那个y字形的图案可以看出来,这应该会是一个重要的具有鲁棒性的真实的特征。
优点4:显而易见,这个方法非常方便可视化。
优点5:代码简洁,已有比较成熟的库。

以上便是全部代码了,足够简单。?
?
Categories
富联新闻
Contact Us
Contact: 富联-富联娱乐-富联注册站
Phone: 13800000000
Tel: 400-123-4567
E-mail: admin@youweb.com
Add: Here is your company address

